【VR】Oculus GoをPCへミラーリングさせる(無線)
先日Oculus Goが家に届きました!
私が購入したのは、これ。
64GBの方を選びました。 俗に言うスタンドアローン型というVR機器になるようです。
カートに入れて、購入完了して数時間で発送しますね!というメールがきました。 大体到着まで5日間ほどで手元に届きました。
「けっこうはやいな!」
中身を見てみるとけっこうシンプルにまとまっていました。 メガネを日頃かけている方でも安心。 メガネをかけている人用のアクセサリーみたいなのも付いていて、 スマホのアプリからOculusの設定をする時に、装着ムービーも丁寧に紹介されていました。
(※ わかりやすいように、画像を載せようかと思っていたのですが、この記事では割愛します。が、その分丁寧に書いてくつもりです! また、後日画像を掲載させていくかもしれません。合わせて詳細も追記していければと思います。)
ここから、"PCへのミラーリング"について順をおって説明します。 今回は以下の記事を参考にさせて頂きました!さっそく先人の方に感謝...!!
Oculus Goの画面をPCにWirelessでミラーリング表示する
準備
まず、色々準備が必要です。 すんなりいけば大丈夫ですが、私はある設定で少し詰まりました... スマホアプリの開発を経験されている方はけっこうすんなりいきそう...
では、まず環境から。 あくまで私の環境ですので、他の環境では試していません。随時、自分にあった環境の設定方法をググる必要があるかもしれません。
環境: Windows10 (デスクトップPC) ブラウザ: Chrome
1. スマホアプリと連携
iPhoneならApp Storeで、AndroidならPlayストアで
Oculusというアプリをダウンロード。

ログインを行い(アカウントを作成する必要があります)、手順に従って連携完了まで行う。
1-2. 開発者モードにする
ミラーリングするにしても、Unityで開発を行うにしても Oculusに対して開発者モードに設定する必要があります。
まず、以下のURLへ移動しログインします。
そうすると、「新しい団体の作成」という画面が表示されるかと思います。 任意の団体名を記入し、送信し、完了させます。
完了すると以下の画面が出てくるかと思います。

一旦これでOKです。
スマホアプリに戻ります。
画面下部メニューの"設定" -> 接続しているOculus(シリアルナンバー付)をタップ
-> ”・・・その他の設定” -> "開発者モード" -> スイッチを"有効化" (青色にする)



これで完了です。
2. Android Studioをインストール
続いては、PCの方です。
色々調べてみると、ミラーリングするだけだったらadbコマンド (Android Debug Bridge)が使用できていれば問題なさそうです。 なので、既にAndroidの開発などをされている方は、不要かもしれません。 ここでは将来的にUnityでOculus Goを開発することを目的にしたいので、一気にAndroid Studioをインストールします。
公式: Android Studio概要
以下のURLに行って、ダウンロードします。
Download Android Studio and SDK Tools | Android Developers

- ダウンロードした.exeを開きます。
- 特に指定がなければ全部デフォルトでインストール&Nextボタン押下で大丈夫です
- 全てのインストールが完了すると、Android Studioを起動します
- ウィンドウ下部にある、Configure -> SDK Manager を選択
- 左メニューAndroid SDKを押下し、タブSDK Platformを選択。
- API Levelが19以上のものにチェックを入れます
- タブSDK Toolsを押下し、LLDBとGoogle USB Driverにもチェックを入れます
- ウィンドウ下部のOKを押下し、Component Installerが開かれインストールが開始されます
ここまでできたらウィンドウを閉じて大丈夫です。
3. adbコマンドを試す
Android StudioをインストールしてSDKもインストールできれば、 Windowsのコマンドプロンプトでadbコマンドが使用できているでしょう。
ここで、付属していたUSBケーブルとPCを接続します!
私の場合はここでadbコマンドが使用できず、 "’adb’は内部コマンドまたは外部コマンド、操作可能なプログラムまたはバッチファイルとして認識されていません"
と、出力...
「なんでやあああああぁぁ!!!」
とか言いながらググりました。
結果、環境変数のPATHが通っていないことが判明。 いつもやってんのに... 普段Windowsあんまり使わないから見落としてた。 (私の場合は早期に環境変数に気づきましたが、PATHがさらに間違っていたから時間とりましたww)
もしコマンドが使用できないなら、コントロールパネルを開いて、 システムとセキュリティ -> システム -> 左メニューのシステムの詳細設定 -> 詳細設定タブ の環境変数(N) -> 環境変数のPATHを選択して編集 -> 新規
ここで私は2つPATHに対して新規で追加。
C:\Users\ユーザ名\AppData\Local\Android\Sdk\platform-tools C:\Program Files(x86)\Android\android-sdk\platform-tools
ちゃんとPATHがは自分で確認してください!! 上記のpathを参考にエクスプローラーからポチポチしていけば確認できかと思います。
そして、いざコマンド実行。
> adb devices List of devices attached xxxxxxxxxxxxxxxxxx unauthorized
「NOOOOOOOOOぉぉぉぉぉ〜〜〜!!!」
なんか権限ないですやん...
まあ、ただadbコマンドは使用できていてOculusは認識しているっぽい。
ふむふむ
ってことは、どっかで権限を有効にしてやるかんじかなと、またググる。
本来?というかAndroid端末であればどうやらUSBデバッグの許可の取り消しなるオプションがあるらしい。 ただ今回はOculusさんだぞ...
「どこを探してもない.... おおおおおおおおおお」
ってなってたらオキュラスのレンズから光が見えた!!!!www
USBデバッグの許可は、Oculusの画面から許可してあげる でしたwww
すげえバカでしたが、まあよしとする。
一応なのですが、adbサービスの再起動として、以下のコマンドを実行させます。
# 停止 > adb kill-server # 起動 > adb start-server
ということで、もう一度デバイスの確認実行。
> adb devices List of devices attached xxxxxxxxxxxxxxxxxx device
OK。
続いてOculusのIPを調べる。 無線LANなのでwlan数値を指定します。 ちなみにeth0は有線。
> adb shell ip addr show wlan0
出力された情報のinetの横にIPが確認できるかと思います。
おそらく192.168.xx.xxみたいに出てるかな?
adbでportを開放
portを開いていきます。
portの範囲は、5555~5585の範囲で奇数を指定したほうがよさそうです。
こちらがadb の仕組みです。
今回は公式で紹介されている通り5555で試します。
> adb tcpip 5555
これでUSBを介して、port5555でTCP/IP 接続をlistenするようにOculusを設定しました。
ここで、PCに接続しているOculusをUSBケーブルを抜きます。
※ 接続切れている場合は、adb connect <IP>:5555 で接続にトライしてみてください。
Vysorの設定
ここまできたら、あとはVysor(バイザー)のインストールと設定のみです。
Vysorとは、ブラウザChromeで動くアプリケーションです。 スマホ画面をパソコンへミラーリングさせるアプリのようです。わたくし初見でした。
まず、ブラウザにインストールします。
すると、chrome://apps/ に追加されていると思います。
起動させます。
起動させたウィンドウ上部にOculusの接続が確認できていればOKです。 もし、確認できていなければ、Settingsの上にあるConnectボタンを押下。
コマンドプロンプトで確認したIPとportを指定して接続します。
これでOculus Goを開始すればミラーリングできているかと思います!!!!!

自分では見えねえよってかんじですがww
Discordの画面共有で友人にみせてあげましたww
当人いわく、「画面見れてるよ!!! ただお前ほどの感動はない」
とのことでしたwww
やはりVRで見れないので、購入してVR体験してもいいかもしれませんね!!
次回は、Unityでのプロジェクト環境構築&作成考えています。
以上.
【k8s】kubernetes 入門 - #04
今回はPodについて勉強していこうと思います。
DevOpsやMLOps、SREなどの肩書を持っている方であれば仕事で使用しているので理解がある方が多いかと思いますが、
他のエンジニアはPodという単語をなんとなく知っているくらいかと思います。
kubernetesを使用していくとも、AWSやGCPの公式ドキュメントではたびたび使用されているような単語ですね。
kubernetesを使用しているクラウドサービスを運用していればもちろん理解しておけなければならないでしょう。
Pod とは?
Podとは、同じ実行環境上で動くアプリケーションコンテナとストレージボリュームの集まりのことです。
Kubernetesクラスタ上でのデプロイ最小単位になります。
これだけ聞いても、馴染みにのない方にとっては、"つまりアプリケーションじゃないの?" とか "運用上どういう考え方でPodとやらをデプロイするべきなのか?" と思うこともあるでしょう。
考え方的なことは後で解説するとして、ここでは、Podが最小のデプロイ単位と覚えておくと良いでしょう。
コンテナの機能
Podについて踏み込んで行く前に、コンテナとOSとの関係をここで簡単にみていきます。
私の記事の#1で、"コンテナはオペレーションシステム(HostOS:kernel)を共有"と説明しました。
【k8s】kubernetes 入門 - #01 - helloworlds
※ ここでは主にコンテナランタイムはDockerを前提に記載します。
コンテナが機能するにあたり、以下のLinuxが持つ機能を利用しています。
- overlayfs
- namespaces
- cgroups
基本的に1つのノードに複数のPod(=複数のコンテナ)がのることは容易に想像できます。
つまりコンテナは、OSカーネルが持っている環境を隔離することができるということになります。
これは、namespacesとcgroupsのOSカーネルの機能が使用されています。
(※overlayfsは割愛)
cgroups
各コンテナは、CPUやメモリといったリソースを制限なく使用できるわけではありませんね。
ここで使用されているのが、Linuxカーネルの機能であるcgroupです。
cgroupはタスクのグループ化、グループ内のタスクに様々なリソース制御を行う仕組みです。
namespaces
ネームスペースは、コンテナを1つの仮想マシンのようにみせるための機能です。
コンテナを区画化し、Linuxカーネルのネームスペースを制御します。
ネームスペース内のプロセスは他のネームスペース内のプロセスとリソースが隔離できることが重要な点です。
これにより、他のノードでも同じ環境を構築することができます。
以下のリソースが分離可能です。
- PID: プロセスID
- Network: ネットワークデバイス、port、ルーティングテーブル、ファイアウォールルールなど
- Cgroup: プロセスの名前空間を分離するためルートディレクトリ
- IPC: System System V IPC, POSIX message queues
- Mount: マウントポイント
- User/Group: ユーザーID(UID)、グループID(GID)
- UTS: Host name、NIS domain name
参考: namespaces(7) - Linux manual page
簡単にまとめ
ここまでくると、このように想像できます。
上記のことは理解できますが、1つ運用面で疑問に思うことができてきます。
"Podに入れるコンテナはどういったものが良いのか?" です。
Podに入れるもの
例えば、AというコンテナとBというDBのコンテナがあったとします。
当然このAとBのコンテナを1つのアプリケーションとして扱う場合、一緒にいれておけばOKと考えますが、
これはアンチパターンになってしまいます。
このアプリケーションに負荷がかかった場合、Podはスケールします。
このとき、フロントエンドを担うコンテナとDBのコンテナを同時にスケールさせてしまいます。
DBの方は他の条件でスケールさせたいとすると、同じPodに入れておくには効率が悪いことになります。
設計時に考えたいのは、"このコンテナはそれぞれ違うマシンに配置されたとしても正常に動作するかどうか" ということです。
- 動作する→ Podを分ける
- 動作しない→ コンテナをまとめて1つのPodにする
必ずしもこの通りではないかもしれまんせんが、基本的には上記を元に設計するのが良さそうです。
(※ アプリケーションやバッチ、APIなどのそれぞれの要件によって、マシンサイズが変動することもありますが、それは違うサービスで実現可能。)
当たり前ですが、Podは違うマシン(ノード)に配置されるということも最初は見落としがちな気がします。
最初の内はマシンが違っていても、動作することを基本的な条件として取り入れておくべきだと思います。
Podの作成してみる
簡単なPodを作成してみます。
適当な場所でYAMLファイルを作成します。
apiVersion: v1
kind: Pod
metadata:
name: kuard
spec:
containers:
- image: gcr.io/kuar-demo/kuard-amd64:1
name: kuard
ports:
- containerPort: 8080
name: http
protocol: TCP
※ minikubeで試しています笑
マニフェストを作成したら、以下のコマンドでapplyします(Podを作成)。
$ kubectl apply -f kuard-pod.yaml -n default
-n はネームスペース指定のオプションです。
作成の確認は以下のコマンドです。
$ kubectl get pod -n default NAME READY STATUS RESTARTS AGE kuard 1/1 Running 0 11m
次にPodの詳細を確認してきましょう。
$ kubectl describe pod kuard -n default
たくさんの情報が出力されるので、簡単にみていきます。
まず一番上に記載されているのが当Podの情報ですね。
Name: kuard Namespace: default Priority: 0 Service Account: default Node: minikube/192.168.58.6 Start Time: Sat, 25 Mar 2023 16:58:11 +0900 Labels: <none> Annotations: <none> Status: Running IP: 10.244.0.5 IPs: IP: 10.244.0.5
次にPod内で動作しているコンテナの情報です。
Containers:
kuard:
Container ID: docker://xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
Image: gcr.io/kuar-demo/kuard-amd64:1
Image ID: docker-pullable://gcr.io/kuar-demo/kuard-amd64@sha256:bd17153e9a3319f401acc7a27759243f37d422c06cbbf01cb3e1f54bbbfe14f4
Port: 8080/TCP
Host Port: 0/TCP
State: Running
Started: Sat, 25 Mar 2023 16:58:17 +0900
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-mwqxn (ro)
次にコンディションです (参考)
Conditions: Type Status Initialized True Ready True ContainersReady True PodScheduled True
次にボリュームです。 当Podのボリュームのタイプなどが確認できます。
Volumes:
kube-api-access-mwqxn:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
続いて、QoSについて。
QoS Class: BestEffort
あまり馴染みがないので、簡単に記載すると、
- BestEffort (優先度が一番低)
- Burstable
- Guaranteed (優先度が一番高)
上記のように値があり、Podをkillする優先度合いのことです。 (Podが複数あり、リソースを60%使用したいPodと90%使用したいPodがあった場合に、killされるPodを判別するために使用される)
今回のマニフェストでは定義していませんが、マニフェストにリソースを定義することが可能です。
(Resource Requests と Resource Limits)
ノード内にあるPodのリソースの状況をKubernetesが確認し、ある条件で判定しているそうです。(これについては詳しく調べていないので、機会があったら記事にしようと思います。)
なので、人間が手動で定義する項目ではないようです。
以下の2つはPodを特定のノードにスケジューリングする際のもの。
Node-Selectorsは、特定のノードにスケジュールするためのもので、
Tolerationsは、特定のノードにスケジュールしないためのもの。
※ こちらもここでは深く触れないので参考はコチラ
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
最後にイベント情報。 ログのようなかんじで、Podの起動がうまくいかない場合などにもエラーが表示されることもあります。
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 12m default-scheduler Successfully assigned default/kuard to minikube Normal Pulling 12m kubelet Pulling image "gcr.io/kuar-demo/kuard-amd64:1" Normal Pulled 12m kubelet Successfully pulled image "gcr.io/kuar-demo/kuard-amd64:1" in 4.327812798s (4.327878355s including waiting) Normal Created 12m kubelet Created container kuard Normal Started 12m kubelet Started container kuard
kuardにアクセス
先程起動させたPodにポートフォワードして、ブラウザからアクセスが可能です。
$ kubectl port-forward kuard 8080:8080
まとめ
今回はPodについて勉強していきました。
kubectlコマンドでは、まだまだたくさんのオプションがあります。
重要そうなコマンドや、便利そうなコマンドは随時別の記事にて記載できたらと思います。
次回は、ヘルスチェックとボリュームについて記載した記事を投稿予定です。
【k8s】kubernetes 入門 - #03
ちょっとDockerの話
Docker: Accelerated, Containerized Application Development
kubernetesのデフォルトのコンテナランタイムであるDocker。
ここでは復習程度に重要な項目をみていきます。
※ インストール方法やDockerの詳細な使い方はここでは割愛します。
Docker image
Dockerのイメージフォーマットは、ファイルシステムレイヤが重なってできています。
この仕組をオーバレイファイルシステムといい、各レイヤはファイルシステムの前にレイヤに対して変更・削除・追加などを行っていくことになります。
この仕組みがあることにより、イメージを作成する際、意識したいポイントがいくつかあります。
- 後続のレイヤで削除したファイルは、イメージ内に存在している
- 各レイヤは、前のレイヤからの差分でる(=依存している)
以下のような場合、レイヤCにはFileAが含まれていないよにういに思いますが、 実際には含まれている。
.
├── レイヤ A ("FileA"というファイルが存在)
│ └── レイヤ B ("FileA"というファイルを削除)
│ └── レイヤ C
レイヤの構成をよく考慮することは、後々の効率性繋がるでしょう。
アプリケーションコンテナ
サンプル用のDockerfileを作成します。
本書にのっとり、kuard (Kubernetes up and running)イメージを作成します。
$ git clone https://github.com/kubernetes-up-and-running/kuard.git $ cd kuard/ $ make build $ mv Dockerfile Dockerfile_org $ vim Dockerfile FROM alpine COPY bin/blue/amd64/kuard /kuard ENTRYPOINT [ "/kuard" ] $ docker build -t kuard-amd64:blue . $ docker images REPOSITORY TAG IMAGE ID CREATED SIZE kuard-amd64 blue c92b95bcf844 17 seconds ago 24.4MB kuard-build latest c28cec9a0481 54 minutes ago 438MB
コンテナを実行
$ docker run -d --name kuard -p 8080:8080 -it kuard-amd64
ブラウザからlocalhost:8080にアクセスできたらOKです。
docker run のオプションは以下。
docker run — Docker-docs-ja 20.10 ドキュメント
クラスタのデプロイ
上記まではdockerのイメージから実際にコンテナを作成することができました。
続いては無課金で利用できるminikubeを使用して、クラスタ作成を行っていきます。
※ minikubeはシングルノードです。つまり、ノード1台分しか構築できないので、今後k8sの分散された機能を試すには、クラウドリソース(AWS, GCPなど)の作成が必要です。
インストールはbrewで↓
$ brew install minikube
インストールが終わったら、
$ minikube start ・ ・ ・ 🏄 終了しました!kubectl がデフォルトで「minikube」クラスターと「default」ネームスペースを使用するよう設定されました
ここまできたらOK!
kubectlコマンドの確認
kubectlのインストールおよびセットアップ | Kubernetes
公式からもインストール方法はありますが、AWSのドキュメントもわかりやすいと思うのでリンクを貼っておきます↓
kubectl のインストールまたは更新 - Amazon EKS
例:(1.23 - aws手順)
$ curl -o kubectl https://s3.us-west-2.amazonaws.com/amazon-eks/1.23.7/2022-06-29/bin/darwin/amd64/kubectl $ chmod +x ./kubectl $ mkdir -p $HOME/bin && cp ./kubectl $HOME/bin/kubectl && export PATH=$HOME/bin:$PATH $ echo 'export PATH=$PATH:$HOME/bin' >> ~/.bash_profile $ kubectl version --short --client Client Version: v1.23.7-eks-4721010
クラスタを見学
ようやく実際にkubectlコマンドを使用します。
$ kubectl get componentstatuses
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health":"true","reason":""}
- controller-manager:クラスタ上での様々なコントローラを動かす役割
- scheduler:各Podをクラスタ内のそれぞれのノードに配置する役割
- etcd:クラスタのsyベテにAPIオブジェクトが保存されるストレージ
今は大体これくらいを理解しておけば良さそう。
続いてノードを取得してみる。
$ kubectl get node NAME STATUS ROLES AGE VERSION minikube Ready control-plane 17m v1.26.1
1つしかないw
本来、Kubernetesのノードは以下のように分類できます。
AWSのEKSであれば、EKSを作成するとマスターノード(AWSがマネージドしている)が作成され、
ユーザが作成したノードはワーカーノードになりますね。
ちなみに上記のコマンド"node"は"nodes"複数形でも単数形でもkubectl は理解してくれます。
確認できたノードについて詳細をみていきます。
$ kubectl describe node minikube
Name: minikube
Roles: control-plane
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
kubernetes.io/arch=amd64
kubernetes.io/hostname=minikube
kubernetes.io/os=linux
minikube.k8s.io/commit=ddac20b4b34a9c8c857fc602203b6ba2679794d3
minikube.k8s.io/name=minikube
minikube.k8s.io/primary=true
minikube.k8s.io/updated_at=2023_01_29T13_51_31_0700
minikube.k8s.io/version=v1.29.0
node-role.kubernetes.io/control-plane=
node.kubernetes.io/exclude-from-external-load-balancers=
ノードの基本的な情報が最初に記載されていますね。
- Conditions:ノード上で動いているオペレーションの情報
- Capacity:キャパシティ
- Allocatable:キャパシティ(割り当て可能)
なんだかCapacityとAllocatableの違いが気になったので、調べてみました。
https://kubernetes.io/docs/tasks/administer-cluster/reserve-compute-resources/#node-allocatable
k8s公式のドキュメント から、 Capacityはノードのリソース量で、 Allocatableは、スケジューリング用に利用可能となるリソースの量(Podに対して割り当てられる量)だと思います。
- Non-terminated Pods:ノード内にあるPod
いったんまとめ
ここまでクラスタを作成し、ノードの中身をちょっとみていきました。
本来AWSのやGCPを利用して、クラスタ作成をすればより実践的に理解ができるとは思うのですが、
ちょっと仕事から離れ、プライベートにてk8sの仕組みに焦点をあてたいので、minikubeにしました。
また、いきなりkubectlコマンドが出てきたりしましたが、ここでは一旦疑問なしにインストールして使用しました。
後々学んでいくk8sの構成などを理解していく時に、より詳しくみていこうと思います。
最後に当ノードにあるPodについて、細かくみていこうと思いますが、続きは次回にしようと思います。
【k8s】kubernetes 入門 - #02
前回の記事↓
今回は #2 ということで、Kubernetesの核となるコンセプトについて簡単に書いていこうと思います。
コンテナAPI
クラウドリソースを扱っているエンジニアなら嫌というほど聞くでしょう。
"可用性" や "スケーラブル"
どんなサービスも信頼性が高いことが求められているように思います。
システムに障害があったとしても、全体に影響しないように設計し、
24365(24時間365日)安定した稼働が求められているように思います。
また、システムのメンテナンスにおいても、これまで深夜の時間帯にサーバーのダウンタイムを設け、
その間にメンテナンス作業を行う。
基本的にサービスは世界中の人が使用しているということであれば、
そのようなメンテナンス作業を設けることはユーザーにとって、あまり都合の良いことではないかもしれません。
これからk8sの核となるコンセプトについて、3つ見ていこうと思います。
イミュータブル (immutability)
immutabilityの単語の意味は、"変化することができない性質" です。
プログラミング(IT)においても同様な意味で使用されることが多いですね。
変更不可のような意味合いを持つでしょうか。
本技術書では、
変更が積み重ねられることはない O'Reilly Japan - 入門 Kubernetes
というような訳され方をしています。
これまでコンピュータとソフトはミュータブルなインフラとして扱われてきたようです。
aptコマンドなどがその例でしょう。
古いものの上に新しいものがコピーされるようなことです。
一方イミュータブルは、一度作成された成果物は、ユーザの更新があっても成果物は変更されないということです。
k8s的にいうと、新しいイメージを置き換えるということになります。
宣言的 (declarative configuration)
続いて、宣言的について。
宣言的の対象的な命令的設定です。
この考え方は、上記のイミュータブルとミュータブルの考え方と同じような関係になります。
命令的設定は、命令の実行によって状態が定義されます。
これに対し、宣言的設定は、望ましい状態を宣言することになります。
このように、イミュータブルと宣言的設定はk8s的考え方として、重要だと思います。
状態を定義することで、変更や間違いに気づくことができ、
命令的設定では難しいソースの管理やコードレビューが適用できます。
間違いが起こった際も、ヴァージョン管理している宣言的状態を戻せばOKでしょう。
命令的設定は、ロールバックの手順も予め準備しなければなりません。
自己回復 (online self-healing system)
k8sは宣言的設定を行ったあと、その状態に一致するよう継続して動きます。
k8sは自己回復することで、オペレータの責任を軽減し、復旧作業をも簡単にさせます。
この3つのコンセプトは、サービスや組織(チーム)のスケールにも対応できることを示しているでしょう。
この後の記事で理解を深めていこうと思いますが、
分離アーキテクチャを重視されているk8sは、組織にとって、誰がどの領域を面倒を見ればよいかより分かりやすくしてくれているように思います。
本書では、上記3つのコンセプトが、
下記3つを提供するためにデザインされたものだと記載されています。
- ベロシティ (Velocity)
- 効率性 (Efficiency)
- 敏捷性 (Agility)
これで、アプリをデプロイする理由がなんとなく理解できたように思います。
続きは、デプロイ方法やk8sの中身に触れていきたいと思います。
前回の記事↓
【k8s】kubernetes 入門 - #01
kubernetes 入門記事。
この記事からタイトル"kubernetes 入門"という記事は、
以下の技術書を元にk8sの理解度を上げるために書いていこうと思います。
※ 初版が2018年と古いですが、他の書籍と比べ、基本要素についてk8s開発者が端的に説明しているので、実践的なコマンドやデプロイ方法などより、要素の役割に焦点を置いて、私の理解含め記事にしようと思います。

kubernetes とは?
そもそもkubernetesが何かというお話です。
kubernetesは、kubeやk8sなどと略して呼ばれることが多々ありますね。
(以下k8sと記載することがあります)
kubernetesとは、一言でいうと、オーケストレータです。
オーケストレータと言われても、オーケストラ?ってかんじですねw
もう少しいうと、コンテナ化されたアプリケーションをデプロイするためのもの。
分散システムが当たり前となり、そのシステムを構築し、デプロイ・メンテを行うタスクが多々あると。
そのタスクをシンプルに行えるのがk8sということになるでしょうか。
全くk8sに触れたことがない方は、"どうやらDockerの仲間らしい" とか "Dockerを簡単に扱えるようにしたもの" みたいなイメージがあるのではないでしょうか。
Docker を使用し、アプリケーション開発をしたことがある人であれば、開発において難儀に思う部分が想像できるかと思います。
今の段階では、k8sとは、コンテナ化されたアプリをデプロイする便利なものくらいにイメージしておけばOKでしょう。
もう少し詳しく
元はといえばk8sはGoogleが開発し、 そして2014年にOSS(オープンソース)化されたようです。
現在では様々な人にサポートされ、色々な分野で導入されているようです。
Kubernetesの名称は、ギリシャ語に由来しており、操舵手などの意味があるそうです。 (なので、アイコンは船の舵なのですね!)
過去から今を考える
従来は物理サーバー上で以下のようにアプリが実行されていました。

この場合、1つのアプリケーションがリソースを多く消費してしまうと、
他のアプリケーションはパフォーマンスが下がり正常に実行されなかったりしてしまうでしょう。
なので、1つの物理サーバーに1つのアプリケーションを実行させることが安全策になるでしょう。
しかし、あるアプリでは特定の時間帯のみ実行されることを想定していたり、
そもそも物理サーバーを多く所有することは運用の負荷にもなりますし、コスト面を考慮してもあまり効率的ではないことが想像できます。
そして、仮想化が主流になりました。

CPU上で複数のVMを実行させることができるので、アプリケーション間の制御(セキュリティレベル)も可能となりました。
Hypervisorは仮想マシン(VM)を作成することができるので、
1つのサーバーに異なるOSを置き、その上でアプリを実行することができます。
なので、VMを1つのセットとして考えると、
上記の物理サーバーの頃と比べて運用やコスト面で優位に扱えることがわかります。
(まあ、要件によっては運用コストが高くなったよ!とか障害時の・・・とか、HypervisorとてKVMやら何やらあるので、AWSのEC2ではどうとかこうとかあるのですが、ここでは細かいことは割愛!w)
ここにきてようやく、コンテナの話です。
仮想化の方との主な違いは、コンテナはオペレーションシステム(HostOS:kernel)を共有することができる点です。
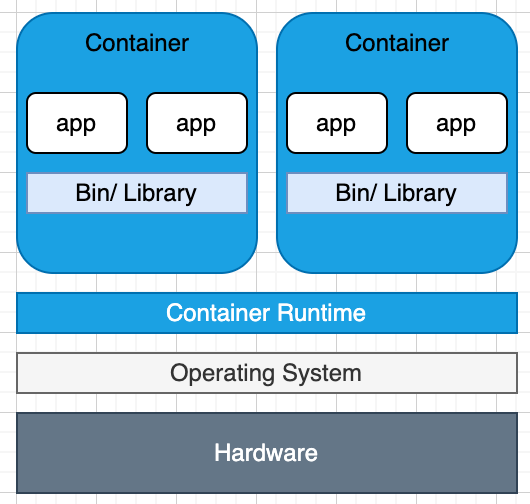
Docker を例とするとイメージしやすいかもしれません。
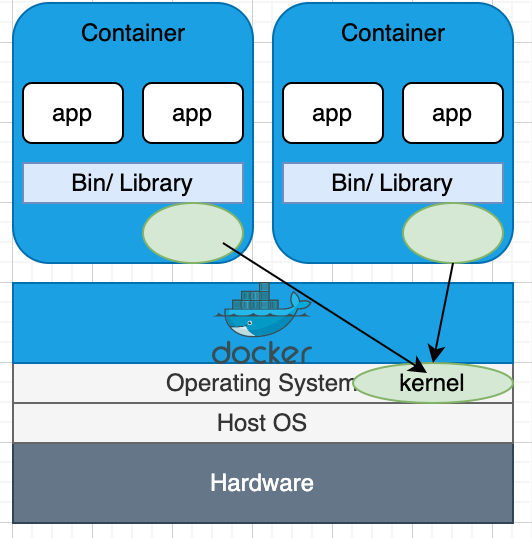
VMと同じようにコンテナでも各自のファイルシステムやCPUの共有、メモリー、プロセス空間等を持っています。
VMではハードウェアのリソースを分割し、仮想環境を分離していますが、
コンテナではカーネルを共有し、アプリレベルでの分離をしています。
このため、高速な起動やリソースの有効活用がより行えるということになります。
ということは、コンテナの方が良いじゃん!!といことになりかねませんが、
メリットばかりでもないというのが現場では感じられるでしょう。
例えば、
VMではそのままのセキュリティ対策を流用できることも少なくはないはずです。
方法は違えど、物理マシンと同様な考え方で構成などを行っていくことができますし、ノウハウも多いはずです。
一方コンテナでは、ネットワークなど扱いがVMとは異なることも多く、
現場レベルでは運用しているアプリケーションを、コンテナ化できるか考慮することが必要となり、 大規模なアプリになればなるほど、移行に掛かる時間はもうなんとやらです・・w
サービス(アプリ)に負荷が掛かれば、オートスケールしなければなりませんし、
コンテナは楽に作成できたとしても、運用されるコンテナが増えるにつれ、 管理をしないといけない数が増え、運用コストも負荷が掛かることになります。
コンテナということは、Dockerイメージなる、イメージを適切に管理しなければなりませんし、
実際に開発している開発者が、開発に集中できるように適切な方法で管理しなければ、
さらに運用にさくコストは増え続けてしまうことになります。
長くなったけど
ここまで、今までのアプリケーションのデプロイ方法までの道筋と言いますか、
アプリが稼働している環境について大雑把に振り返ってみましたが、k8sの話がまだですねw
まあ、つまり、このコンテナ型の運用につきk8sが活躍してくるといった具合です!!
本来もう少し技術書の沿った内容をこの記事で記載しようと思いましたが、
長くなってしまったので、今回はここまでにします。
次回は1章から気になった・重要な・詳しく理解していきたい点について記載しようと思います。
過去のDockerに関する記事はコチラ↓
【初期設定 - mac】ターミナルの設定
※ かなり期間が空いてしまいまいしたが、久しぶりに更新
※ 今回は自分用のメモ記事
前提
- macOS
- Big Sur v11.7.2
概要
今回はMacのターミナルが最初ダサい問題をシンプルに解決していきます。
個人的にカスタマイズし過ぎると、また新たに初期設定をする際にメモしておく設定や 時間がかかるので、なるべく最低限の設定を行うことを心掛けていますw
テーマ(theme)を探す
基本的にターミナルにはデフォルトでテーマが用意されているようですね。

まあこれでも良いのですが、ちょっと見にくそうなカラーがベースのものばかり。
良いテーマはないかなーと探してみると同じようなテーマばかりがヒットします。
んー、そういうば数年前に見かけたGithubで公開されいてるテーマを思い出しました!
なんとか探すこと数十分....
あった!!!↓
かなり多くのテーマがあるので、自分好みのテーマを探すことができそうです。
今回は、試しに "Espresso" を設定してみようと思います!
テーマをダウンロード
このリポジトリをクローンするのは沢山テーマが入っているので無駄なので、 自分の設定したいテーマのみをダウンロードしてきます。
themesディレクトリいくと、"{テーマ名}. terminal" というファイルがあるので、
今回はEspressoを探してローカルに落としてきます。
(.terminalというファイルのみのダウンロードで大丈夫です。もしくは先に任意のファイルを作成しておき、中身をコピペで持ってきてもOKですね。)
ファイルはどこにおいても大丈夫ですので、任意のフォルダに入れておくのが良いでしょう。
ターミナルからデフォルトに設定
ターミナルの環境設定から、"プロファイル"タブ→ 左のテーマの下部から読み込みをします↓ (先程落としてきた.terminalを指定)
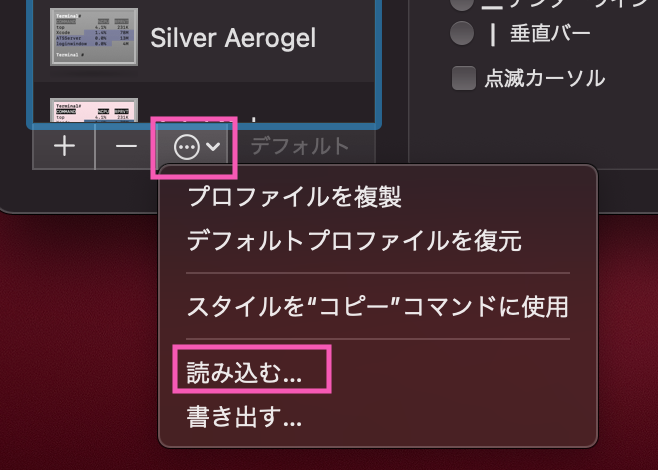
これでデフォルトにセットすればOK!
ターミナルを再起動させればテーマが適用されているでしょう。
コマンド実行時にカラーが反映されない場合
以下の環境変数を.zshrcなどに追記しておけばOK。
export CLICOLOR=1
【Terraform】各ヴァージョンについて簡単に
概要
Terraformはヴァージョンによって、微妙に記述が違っていたりすることが多く、 特にチーム(複数人)で運用する場合は、ヴァージョンの統一感をもっておいたほうがいい。
よって、その記事がどのヴァージョンなのか知ってくおくといいかもしれない。
公式のリリースノートは、Githubにて公開されているので参考に。↓
https://github.com/hashicorp/terraform/blob/master/CHANGELOG.md
詳細
現在(2020/12 時点)で肝になってくるヴァージョンは以下。
- 0.15.0 (2020/12 時点 Unreleased)
- 0.14.0 (2020/12 時点 released)
- 0.13
- 0.13.5(2020/11 時点 released)
- 0.12
- 0.11以下
この記事記述時の最新は、2020/09/30にリリースされた0.13.4となる。
HCL
Terraformは、HCL(HashiCorp Configuration Language)というJSON互換の記法で記述する。 コードというわけでなくYAMLみたいなイメージで、設定を記述するかんじ。
とはいえ、管理するクラウドリソースが多くなれば、記述の方法を考慮しておく必要がある。(複数のアカウントや、環境、拡張性、複数のクラウドソリューションなどを考慮)
また、ヴァージョンの更新において、単にTerraform cliバイナリを更新しても、既存のHCL1(0.11以前)で記述されたTerraformがterraform apply時にエラーが出力される場合も考えられる。
プロバイダー
プロバイダーというものがあり(簡単に言うとプラグイン的な位置づけ)、例えばAWSやGCP, Azure, Herokuなどの各プラットフォームにTerraformで定義した内容をプロバイダーにプッシュする。
プロバイダー一覧: https://www.terraform.io/docs/providers/index.html
terraform init実行時に自動的にインストールされるため、Terraformユーザー側で特に気にすることはないが、
Terraformのヴァージョン自体のアップグレードで、プロバイダー側が未対応の場合もあり、警告やエラーが出力される。
ヴァージョンのアップグレードについて
基本的には、Terraformの公式ドキュメントに基づく。 例: https://www.terraform.io/upgrade-guides/0-12.html
ただし、tfenvというTerraformのヴァージョン管理ツールをローカルにインストールし、ヴァージョン管理すると便利かもしれない。
v0.11
※11系は省略。
v0.12
言語機能が拡張され"HCL12"が導入された。(ヴァージョン2に更新された。)
First-Class Expressions
"${var.foo}"
↓
var.foo
リストやマップもダイレクトに変数に格納可能できるようになった。
users = var.users books = ["book_1", "book_2", "book_3"]
Rich Value Types
以前は、Terraformが自動的に期待される型変換をしていたが、 0.12以降型の指定が行えるようになった。 また、以下の例のようにオブジェクト構造のタイプも記述できるようになった。
variable "networks" {
type = map(object({
network_number = number
availability_zone = string
tags = map(string)
}))
}
length Function
https://www.terraform.io/docs/configuration/functions/length.html
> length([])
0
> length(["a", "b"])
2
> length({"a" = "b"})
1
> length("hello")
5
resource "google_compute_address" "practice-int" {
count = 2
...
}
#### ↓以下は 0.11 以前
resource "google_compute_instance" "practice" {
count = "${google_compute_address.practice-int.count}"
...
}
#### ↓以下は 0.12 以降
resource "google_compute_instance" "practice" {
count = length(google_compute_address.practice-int)
...
}
Dynamic blocks
公式の記載は以下。 https://www.terraform.io/docs/configuration/expressions/dynamic-blocks.html
ベストプラクティス的には、dynamicブロックの多用は避けて、再利用のできるmoduleなどにおいてはユーザー(読み手)に優しくなるので使用を推奨するとのこと。
v0.13
プロバイダの構成(書き方)
#### AWS
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 3.0"
}
}
}
# Configure the AWS Provider
provider "aws" {
region = "us-east-1"
}
#### GCP
provider "google" {
project = "my-project-id"
region = "us-central1"
}
また、AWSのクレデンシャルについては、公式のココを参考にすること。 余談ですが、Kubernetesのプロバイダーも公式にあって面白そうでした。
depends_on for modules
module ブロックの中で "depends_on "と "count" 、 "for_each" が使用できるようになった。
Custom Validation Rules
変数ブロック内に、任意のカスタムルール(ヴァリデーション)を指定できる。
variable "image_id" {
type = string
description = "The id of the machine image (AMI) to use for the server."
validation {
condition = length(var.image_id) > 4 && substr(var.image_id, 0, 4) == "ami-"
error_message = "The image_id value must be a valid AMI id, starting with \"ami-\"."
}
}
↑公式サンプル引用
例えば、AWSのami imageなら、規則を「最初の5文字は"ami-"だよ」など指定できる。
コマンドについての変更
■ terraform import
オプションの -provider が使用不可になった。
環境
Macであれば、Mac OS 10.12 Sierra以上が推奨されている。
v0.14
v0.14系はv0.13のリリースから早々にリリースされたよう。 なので、v0.13の変更点は大幅なアップグレードが少なくなっている印象。
sensitive入力変数の追加
sensitiveは、セキュリティ面を考慮された使い方になりそう。
terraform planを実行した際、標準出力させたくない値を(sensitive)として出力させることができる。
※例としてAWSのVPCのCIDRなど。
##### 記述例
variable "user_information" {
type = object({
name = string
address = string
})
sensitive = true
}
##### アウトプット例(terraform plan)
Terraform will perform the following actions:
# some_resource.a will be created
+ resource "some_resource""a" {
+ name = (sensitive)
+ address = (sensitive)
}
ロックファイルの追加
terraform init実行時に、ロックファイルが生成される。
このファイルには、プロバイダー情報が記載されている。
プロジェクト内で aws = 3.1.0を許可しterraform init実行後、ヴァージョンを書き換えterraform initするとエラーが出力される。(= 生成されたロックファイルとヴァージョンの相違が起こるため。)
なので、仮にプロバイダーのヴァージョンを変更させたい場合などは、terraform init -upgradeを実行して動作確認をするみたい。
terraform plan / apply 時の差分確認
terraform plan / applyの実行時、以前のヴァージョンまでは変更箇所のすべてが標準出力されていたが、
v0.14からは、差分レンダラー(変更箇所のみ簡潔)が追加された。
最も関連性の高い変更と識別コンテキストのみを表示するようになった。
逆に、すべて確認したい場合は、環境変数のTF_X_CONCISE_DIFFを0 にすると良い。
以上.
【Airflow】入門 part.1 - 番外編 CeleryとFlower
概要
前回の記事で、起動が確認できました↓
Airflowの起動に合わせて、Flowerというダッシュボードも起動しています。
Flowerとは?
Flowerとは、タスクやワーカー数の調整などを行うWebベースのツールです。
Celeryとは?
Celery(セロリ) という、Python製でタスクキューベースの分散処理フレームワークのこと。 worker daemonを待機させてasync処理の仕組みを作ったり、beat daemonを起動して定時バッチ処理を組んだりすることが可能。
Flower+Celeryの実現で、redisをDockerファイルに定義してインストールしていたことになる。
docker-compose-CeleryExecutor.ymlを配置
docker-compose-CeleryExecutor.ymlというファイルを任意のディレクトリに配置します。
## 例 $ mkdir test-airflow $ mv docker-compose-CeleryExecutor.yml ~/test-airflow/
コンテナの構築・起動
docker-compose-CeleryExecutor.ymlを配置したディレクトリで以下を実行。
$ docker-compose -f docker-compose-CeleryExecutor.yml up -d
以下にように、doneと表示されればおk。
Creating network "test_20200415_default" with the default driver Pulling redis (redis:5.0.5)... 5.0.5: Pulling from library/redis b8f262c62ec6: Pull complete 93789b5343a5: Pull complete 49cdbb315637: Pull complete 2c1ff453e5c9: Pull complete 9341ee0a5d4a: Pull complete 770829e1df34: Pull complete Digest: sha256:5dcccb533dc0deacce4a02fe9035134576368452db0b4323b98a4b2ba2d3b302 Status: Downloaded newer image for redis:5.0.5 Pulling postgres (postgres:9.6)... 9.6: Pulling from library/postgres 48839397421a: Pull complete 0cf8a1bc2b87: Pull complete 73498a4e88b3: Pull complete 497c518cf27d: Pull complete 67fdd1391d2e: Pull complete eced13f1b460: Pull complete d5a83883f95d: Pull complete 5a290fef01b8: Pull complete 60611a60649a: Pull complete ab7b2445b4d1: Pull complete a609de04bec9: Pull complete 0544058c2b5d: Pull complete facb5fc91659: Pull complete cefa49d68ba7: Pull complete Digest: sha256:df815e77bcd2da9fa1835a751eadaaccfa0c8ebbe92605a5566a5a2d20950afa Status: Downloaded newer image for postgres:9.6 Pulling webserver (puckel/docker-airflow:1.10.9)... 1.10.9: Pulling from puckel/docker-airflow bc51dd8edc1b: Pull complete dc4aa7361f66: Pull complete 5f346cb9ea74: Pull complete a4f1efa8e0e8: Pull complete 7e4812fc693b: Pull complete ff8fd055a548: Pull complete c9215f8e7f2f: Pull complete cab2fe472084: Pull complete 1f03789c1e57: Pull complete Digest: sha256:30e7cb9744ad367c54ae30a379fa46c9df4ea582bf2fcb96604adfc2760be79a Status: Downloaded newer image for puckel/docker-airflow:1.10.9 Creating test_20200415_redis_1 ... done Creating test_20200415_postgres_1 ... done Creating test_20200415_flower_1 ... done Creating test_20200415_webserver_1 ... done Creating test_20200415_scheduler_1 ... done Creating test_20200415_worker_1 ... done
dockerのimageとコンテナを確認
$ docker images REPOSITORY TAG IMAGE ID CREATED SIZE postgres 9.6 6c8b19735285 2 weeks ago 200MB puckel/docker-airflow 1.10.9 3e408baf20fe 2 months ago 797MB redis 5.0.5 63130206b0fa 7 months ago 98.2MB
$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 95f0df46cbc4 puckel/docker-airflow:1.10.9 "/entrypoint.sh work…" 39 seconds ago Up 39 seconds 5555/tcp, 8080/tcp, 8793/tcp test_20200415_worker_1 a75fc01c3f42 puckel/docker-airflow:1.10.9 "/entrypoint.sh sche…" 40 seconds ago Up 39 seconds 5555/tcp, 8080/tcp, 8793/tcp test_20200415_scheduler_1 9f8818470c01 puckel/docker-airflow:1.10.9 "/entrypoint.sh flow…" 40 seconds ago Up 40 seconds 8080/tcp, 0.0.0.0:5555->5555/tcp, 8793/tcp test_20200415_flower_1 63a2161a9817 puckel/docker-airflow:1.10.9 "/entrypoint.sh webs…" 40 seconds ago Up 40 seconds (healthy) 5555/tcp, 8793/tcp, 0.0.0.0:8080->8080/tcp test_20200415_webserver_1 067ae0133033 redis:5.0.5 "docker-entrypoint.s…" 41 seconds ago Up 40 seconds 6379/tcp test_20200415_redis_1 35dc9542f790 postgres:9.6 "docker-entrypoint.s…" 41 seconds ago Up 40 seconds 5432/tcp test_20200415_postgres_1
postgresのヴァージョン指定などをしたい場合は、さきほど配置したdocker-compose-CeleryExecutor.ymlの中身を編集することで、ヴァージョンの指定が可能だと思います。
ここまで確認できたら、一旦ブラウザでもUIが表示されるか確認します。
ダッシュボードの確認
起動できたら、↑上記にアクセスすると Flowerのダッシュボードが観覧可能です。
<project_name>/ ├── dags ## ← ここにDAGを定義するファイルを作成していく └── docker-compose-CeleryExecutor.yml